主页 > imtoken官网注册 > 什么是哈希算法
什么是哈希算法

什么是哈希算法
散列算法(Hash algorithm, Hash formula, hash algorithm, message digest algorithm)将一个任意长度的二进制值映射为一个较短的定长二进制值比特币采用的哈希算法是,这个小的二进制值称为散列值。 哈希值是一段数据的唯一且极其紧凑的数字表示。 如果您对一段明文进行哈希处理,甚至更改其中的一个字母,则后续哈希将产生不同的值。 在计算上不可能找到散列为相同值的两个不同输入,因此数据的散列可用于检查数据的完整性。 一般用于快速查找和加密算法。
哈希算法的特点

哈希表根据设定的哈希函数H(key)和冲突处理方法,将一组关键字映射到一个有限的地址范围内,并以关键字在地址范围内的映像作为表位记录的存储,这表称为散列表或散列,得到的存储位置称为散列地址或散列地址。 作为一种线性数据结构,与表和队列相比,哈希表无疑是一种更快的查找。
通过将单向数学函数(有时称为“哈希算法”)应用于任意数量的数据而获得的固定大小的结果。 如果输入数据发生变化,哈希值也会发生变化。 哈希可用于许多操作,包括身份验证和数字签名。 也称为“消息摘要”。
简单解释:散列(Hash)算法,即散列函数。 它是一种单向密码体制,即从明文到密文的不可逆映射,只有加密,没有解密。 同时,哈希函数可以改变任意长度的输入,得到固定长度的输出。 散列函数的单向特性和输出数据的固定长度使得生成消息或数据成为可能。
哈希算法(散列算法或消息摘要算法)是一种用于信息存储和查询的基本技术。 它是一种基于哈希函数的文件构造方法,可以实现对记录的快速随机访问。 它将给定的任意长度的密钥映射成固定长度的哈希值,一般用于认证、认证、加密、索引等。其主要优点是计算简单、预处理时间短、内存消耗低、匹配搜索速度快、易于维护和刷新,支持大量匹配规则。

哈希算法的属性
(1) 单向。 也就是说,给定一个输入数字,很容易计算出它的哈希值,但是众所周知,一个哈希值无法按照同样的算法得到原始输入数字。
(2)抗碰撞性弱。 也就是说,给定一个输入数字,使用相同的方法找到另一个产生给定数字的哈希值在计算上是不可行的。
(3) 抗碰撞性强。 即对于任意两个不同的输入数,按照相同的算法计算出相同的哈希值在计算上是不可行的。
哈希算法的性能
哈希算法搜索方式实现简单,存储要求小,支持范围匹配和动态更新,但其效率受规则分布和规则数量影响较大。 当有冲突时,查找时间比较长。
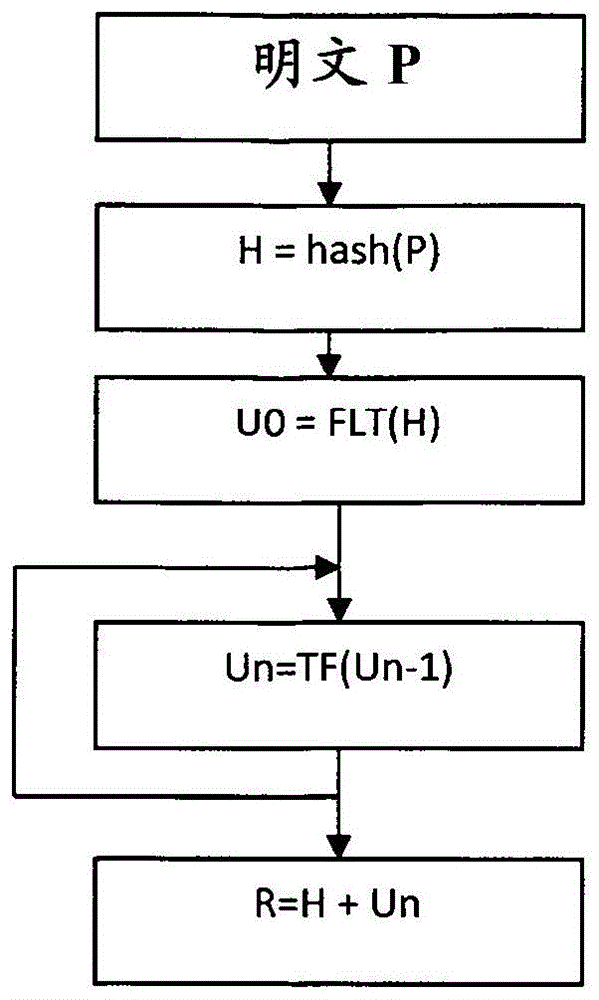
哈希算法的计算方法
用于生成某些数据(例如消息或会话项)的哈希值的算法。 使用好的散列算法,输入数据的变化可以改变结果散列值中的所有位; 因此,散列可用于检测数据对象(例如消息)中的修改。 此外,良好的散列算法使得构造具有相同散列值的两个相互独立的输入在计算上是不可行的。 典型的哈希算法包括 MD2、MD4、MD5 和 SHA-1。 哈希算法也称为“哈希函数”。

另请参阅:基于散列的消息身份验证模式 (HMAC)、MD2、MD4、MD5、消息摘要、安全散列算法 (SHA-1)。
MD5 一种行业标准的单向 128 位哈希方案,由 RSA Data Security, Inc. 开发。它被各种点对点协议 (PTP) 供应商用于加密身份验证。 散列方案是一种转换数据(例如密码)的方法,其结果是唯一的并且不能返回到其原始形式。 质询握手身份验证协议 (CHAP) 使用质询响应并对响应使用单向 MD5 散列。 通过这种方式,您可以向服务器证明您知道密码,而无需通过网络发送。
Challenge Handshake Authentication Protocol (CHAP) 一种用于“点对点协议 (PPP)”连接的质询-响应身份验证协议,在 RFC 1994 中有所描述。该协议使用行业标准 MD5 哈希算法对质询字符串的组合进行哈希处理(由身份验证服务器发出)和响应中的用户密码。
点对点协议

用于通过点对点链路传输多协议数据报的行业标准协议套件。 点对点协议 (PPP) 记录在 RFC 1661 中。
另请参阅:压缩控制协议 (CCP)、远程访问、征求意见 (RFC)、传输控制协议/Internet 协议 (TCP/IP)、自治隧道。
哈希算法的问题
当使用哈希算法进行分类时,需要考虑不同关键字之间哈希值可能存在的地址冲突。 解决冲突一般采用开放式寻址方式,即建立冲突解决区,在冲突解决区中使用链表存储冲突的关键字。 如图1所示,当不同的输入产生相同的Hash值时,最后输入的数字将以链表的形式存储在冲突解决区中。 冲突的次数越多,Hash 值后面的链表就越长。 在进行信息检索时,如果需要的信息是否存储在冲突解决区中,由于输出的是输入的哈希值,因此需要遍历冲突解决区中的链表。 因此,传统的用于网络中数据包分类的Hash算法仍然存在以下问题:当hash算法选择不当时,可能会引起更多的碰撞,导致性能下降,最坏的性能无法得到保证: 大:无法针对不同的规则集进行优化以获得最小的冲突率。
尽管已经提出了多种改进的解决方案比特币采用的哈希算法是,如双Hash机制、可扩展的Hash算法等来解决这些问题。 然而,当Hash算法应用于海量信息查询时,上述效率低下的问题仍然存在。